Reference Architectures
Reference architecture's are useful to deliver reliable code consistently. They consist of a prescribed pattern for laying out an n tier software architecture that a team can easily learn to adopt. Over several iterations they become battle tested increasing their reliability and rapidly speeding up development of new projects or additions to existing projects.
I've build several reference architectures in the past adapting them each time to the changes we've seen over the years in .NET and even pre-.NET (VB6).
Project Black Slope is soon to be the latest iteration in a series of these architectures.
Black Slope? What?
I'm a skiing fan, but I struggled to learn to ski black slopes. They are steep, narrow and tricky to navigate. Throw in some moguls, some trees and the challenge is increased. But, once you get into it, and with a little experience, black slopes get easier and easier!
Building software architecture for me is similar, it's taken a few tough experiences to get to a point where I've learnt what works well and what can potentially cause problems.
Black Slope is a reference architecture designed for building C# .NET Core API's.
Design Principals

Simple
I favor more lines of simple code over fewer lines of complicated code. The software developers on our teams or the developers that will need to maintain the code someday are not all coding geniuses, its true. KISS (Keep It Simple Stephen) is a well known design principal and is a core principal for Black Slope, which is unashamedly simple.
Maintainable
All code should be maintainable. The idea with this architecture is that I should be able to come back several months later and easily be able to make changes. Organization and standardization of code becomes very important. The code base should have low cyclomatic complexity and low technical debt. There are various tools in the market to help measure this. If you aren't doing static code analysis and measuring the quality of your code, you should be.
Portable
The code should be written in such a way that if you need to isolate specific end-point(s) and potentially host them individually you can do so with ease. Each layer in the architecture is portable and through inversion of control (IoC) and dependency injection (DI) can be replaced with completely different implementations. Having portable code will help to achieve a micro service approach should that be required.
Testable
Every layer in the architecture needs to be unit testable. There should be 100% test coverage so that any changes made to the code base in the future can be done with a certain level of confidence. Writing quality unit tests and achieving full coverage is difficult but highly beneficial. Test writing should not be done as an after though or as a secondary task. Try to take a test driven development (TDD) approach and write tests with your code.
Domain Driven Design (DDD)
DDD is gathering knowledge about a given business domain and producing a software model that mirrors it. Entities (domain models) are grouped together into logical groups called bounded contexts.
Anemic vs Domain Model
- Anemic models are often seen as anti-patterns since they lose all benefits of a true object oriented (OE) domain model.
- True OE Domain Models are difficult to build and require a deep knowledge of the system being built and a deep level of experience in OE design. This is often not always possible for every team.
For this reason I am in favor of an anemic model. Black Slope uses a layered architecture with presentation, application, domain and infrastructure layers.
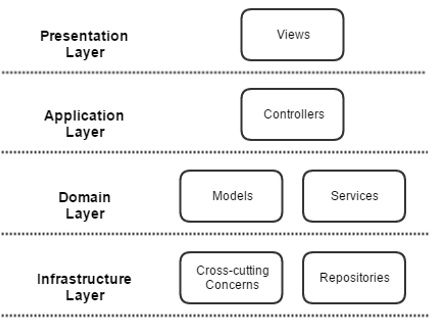
Application Architecture

Presentation Layer
I'm not going to say much about this layer since the reference architecture is focused on Application, Domain and Infrastructure. It exists on the diagram to highlight its role and interaction with the rest of the application architecture.
Application Host
A simple web or console application is used to "host" controllers. 1 or more controllers can be used and multiple host applications can be created to establish a micro-service pattern, if that is required. If it is not you can host multiple controllers within the same host application. Host applications are responsible for the following.
- Logging
- Authentication
- Caching
- Request/Response filtering
- Application Configuration
- Mapping Configuration
- Telemetry
- API Documentation
Application Layer
The .NET WebAPI controllers are responsible for the following.
- Accepting a request
- Validating the request
- Executing a method in Domain Layer Service
- Mapping Domain Objects to Output Models
- Returning a response
Every controller should also handle the following cross cutting concerns.
- Authentication / Authorization using filters
- Error handling
- Logging
- Route and Version control
Domain Models returned by the Domain Layer Service are being mapped to Output Models.
Input Models are instantiated by de-serializing the JSON request and may also use be mapped to a Domain Model, if required.
Domain Layer
Domain Objects are anemic, meaning they are Plain Old CLR Objects (POCO's). They are entities containing properties and no methods or business logic.
Services are responsible for one or more of the following:
- Executing business logic
- CRUD using a Repository
- Mapping Repository DTO Models to Domain Models
- Logging
- Error handling
Infrastructure Layer
Repositories are responsible for connecting to a data source. The data source can be a database, a flat file even another service. The idea behind repositories is to create a separation of concern since repositories can change. This change can then be affected without any disturbance to upstream code. I'm not talking about a change from MS SQL Server to Oracle, this almost never happens. I'm talking about instances where you are unsure of the data source but need to put something in place. Perhaps a mock file which will one day be changed to a service. Or perhaps misinformation led you to use a database table when it was later discovered that flat file feed exists and is preferred.
Data Transfer Objects (DTO's) are used to model the data being retrieved and are also POCO's.
Sample Code
Sample code is currently not available since this reference architecture is a work in progress. I'll publish a follow up post once the code is available via GitHub.
Why is this important?
Building your own reference architecture is important because it will help you to deliver consistently and reliably. Delivery velocity will be increased when team members use the reference architecture they are now familiar with on future projects. New team members are easily onboarded by leaning how the reference architecture works first before tackling changes to new/existing code immediately. Once the reference architecture has gone through several iterations it becomes battle tested, increasing reliability. There is no longer a need to "re-invent the wheel" on future project.
Reference architectures are not a silver bullet and are not suited for all application requirements. The goal is to build the reference architecture in such a way that it will cater for 80% of your requirements and have it as a solid base that can be adapted for the other 20%.
-SW